 International
International Finland
Finland Bangladesh
Bangladesh
AWS Lambda Use Case
In this Career Genese project we have used AWS Lambda to run our own code on Amazon’s servers, so we don’t need to host the code by ourselves. The best part of using it as we don’t have to pay a dime when our Lambda function isn’t being triggered and only need to pay for computation time.
AWS Lambda Use Cases in this project:
- Automated Backups
- Serverless Website
- File Conversion
- Simple Email Service
AWS Lambda Architecture of Career Genese
Description of type of serverless microservice
As there are different microservice available in AWS, we have used AWS Lambda and API gateway as a serverless microservices. The API of a serverless microservice is the central entry point for all client requests. The application logic hides behind a set of programmatic interfaces, typically at REST web services API. This API accepts and processes calls from clients and might implement functionality such as traffic management, request filtering, routing, caching, and authentication and authorization.
AWS Lambda let us run code without provisioning or managing servers. Lambda is highly integrated with API Gateway. The possibility of making a synchronous call from API Gateway to AWS Lambda enables the creation of fully serverless applications and it is described in our documentation.
Total estimated number of events per month:
AWS Lambda triggers are merely actions caused by specific events that will further trigger the lambda function. Any work that triggers the lambda function is an event. And our Lambda functions have approximately 10 thousand events that generate per month. For example, daily personal information submission, exam page submission, confirmation and notification email.
Description of any challenge or customer objection overcome to drive a lambda adoption:
When we introduce AWS Lambda to our customer they were quite impressed by the service but they told us that they will not be using this service because Lambda is quite complex for the developers who are not familiar with AWS.
The number of Lambda functions deployed.
In this task, we have a sum of 7 lambda capacities, which continue with various activities.
Following are the various list of our function that are used to create this application :
- Carer_genese_question_collection
- careeer_genese_SES
- carer_genese_questiom_answer
- Interncareerreturn2
- Carer_genese_cognito
Deployment Patterns: At least 5 functions, Use of best practice deployment application model (SAM)
We had to manage diverse kind of AWS administrations which is recorded beneath:
Lambda function, DynamoDb,API Gateway, Cognito Service, Simple Storage Service, Simple Email Service.Additionally Serverless. Moreover, AWS Serverless Application Model (AWS SAM) is utilized which is an open-source system we have to make utilization of it to manufacture and convey AWS serverless applications. Code Commit, Code Build, Code pipeline are utilized to mechanize programming.
Workload
Workload 1: Connection with at least 3 other AWS Services
AWS Lambda functions act as a backend to the application. This application utilizes other AWS services and resources that are organized and manipulated by lambda functions. An application uses DynamoDB tables for storing data and records. Lambda is responsible for reads and writes of data from and to the database.
For storing static files, AWS storage service S3 is used and all the GET and PUT operation is done by Lambda functions. Cognito is used for signup and sign in whereas Amazon SES is used to notify the administrator if an event is triggered in Lambda function.W
Workload 2: Use of servers or containers only in supporting roles
Since this application is absolutely serverless, all the application rationale live inside lambda improve the performance, minimize the complexity and avoid of using the recursive code of our function. There is no requirement for any servers or holders in any sort of jobs or assignments in the application.W
Workload 3: Serverless workload should use AWS Lambda to handle and process the core data flow for the system
Every single backend rationale that the application depends on is facilitated in AWS Lambda. All the logic behind DynamoDB table read and writes, S3 GET and PUT, tasks with Cognito Admin User creation and so on resides inside lambda functions we have used.W
Workload 4: Automating Infrastructures provisioning and managing is not serverless
AWS Lambda serves client side with appropriate data queries, user registration, and many other application tasks. Automation of Infrastructure provisioning and management is not applicable in this use case.
Solution Characteristics 1: IAM Policy Definition
In this policy, we have utilized diverse IAM approaches to connect it with the IAM Roles to execute necessary tasks in Lambda functions. Using the permissions policy associated with this role, we can grant our Lambda function the permissions that it needs. Different Policies Used are:
- AttendanceCognitoPolicy(Inline Policy)
- AttendaceDynamodbPolicy(Inline Policy)
- ses-full-access(Inline Policy)
- AWSS3DFullAccess(AWS Managed Policy)
- AttendaceRecognitionPolicy(Inline Policy)
- AttendaceS3Policy(Inline Policy)
- AttendaceSESPolicy(Inline Policy)
Solution Characteristics 2: Managing Failed Executions
A Lambda capacity can fall flat for any of the accompanying reasons:
- The capacity times out while endeavoring to achieve an endpoint.
- The function fails to successfully parse input data.
We have used python boto3 library in our code. How the exemption is taken care of relies on how the Lambda work was invoked. In this task, some of these event sources are set up to invoke a Lambda function synchronously and others invoke it asynchronously. In specific cases, possibly the info parameters might not be right and code rationale may not consent to the information. In such case, lambda distinguishes the special case and returns a fitting message to the customer side.
Solution Characteristics 3: Management of Multiple Microservice functions
- The API of a microservice is the central entry point for all client requests. The application logic hides behind a set of programmatic interfaces, typically a RESTful web services API.
- Since clients of a microservice are served from the closest edge location and get responses either from a cache or a proxy server with optimized connections to the origin, latencies can be significantly reduced. However, microservices running close to each other don’t benefit from a CDN. In some cases, this approach might even add more latency. It is a best practice to implement other caching mechanisms to minimize the latencies.
- Amazon DynamoDB is used to create a database table that can store and retrieve any amount of data and serve any level of request traffic.
- The Server Side Logic is written in Lambda functions, which are independent microservice functions of AWS.
Solution Characteristics 4: VPC vs No-VPC and concurrency
Lambda capacities are not put in any VPC’s as the application doesn’t have to interface to any servers that require VPC Secure Environment. Regarding concurrency limits, the default limit of 1000 concurrent executions is enough for a current use case. We might need a limit increase in the future for Higher Performing Microservices.
Solution Characteristics 5: Monitoring of Alarms and Metrics
- For Monitoring the execution of lambda functions, we have used CloudWatch Service of AWS.
- We have monitored different CloudWatch metrics of Lambda by the Name of Function.
- Name of Different Metrics that we monitored for our Lambda includes:
- Invocation per lambda function
- Duration of execution of lambda function
- Error in a lambda function
- Throttles to manage the flow of execution
TCO Analysis:
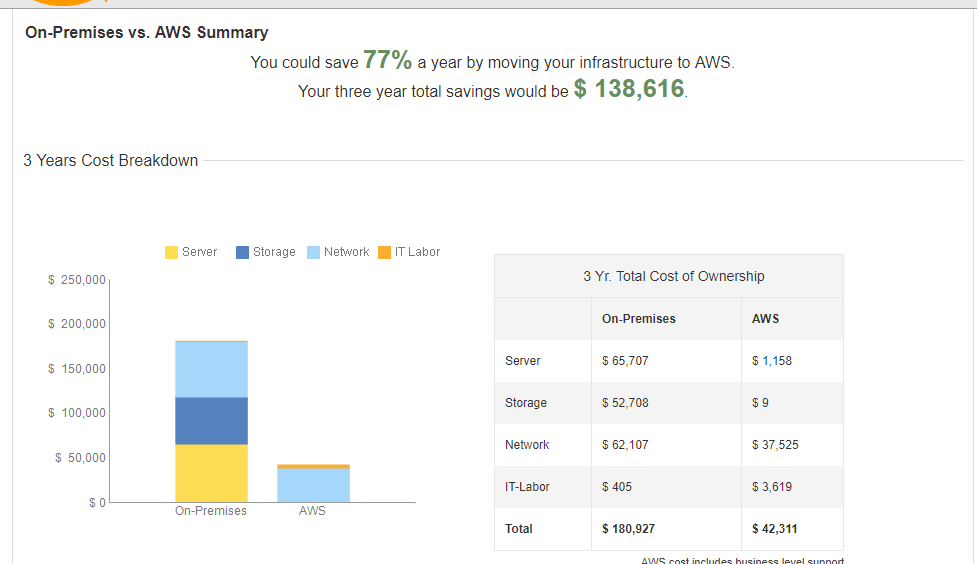
TCO analysis helps us to know the cost that we can save by using the use of Amazon Services. As we can see in the figure 77% of a yearly cost has been saved by moving our System in the AWS.
After moving in the AWS we still saw the way to reduce the cost and we moved towards the serverless service of the AWS, through which we successfully saved $1158 more by integrating with the serverless of AWS.
Dynamo DB Use Case
Application Description:
This recruitment Project is hosted as a serverless in the AWS platform. We have opted Dynamodb as the data storage because dynamodb is a NoSQL database service provided by AWS, and it was quite efficient for the use-case of our client.
The tables we have created during the course of our project development are listed below:
- carer_genese_personaldetail2
- carrer_genese_intern_questions
- final_recruitment_portal
1. Description of Primary Key design for the Tables and Indexes:
Table 1: carer_genese_personaldetail2
Main Table:
Hash Key: Uid
This table stores the personal information of the applicant details. Uid has been used as a hash key which is efficient to perform query operation in the main table and also this table has a minimal number of data stored.
Table 2: carrer_genese_intern_questions
Main Table:
Hash Key: id
This table stores the question collection which is retrieved while the applicant gives their exam. “Uid” is used as ‘Hash Key’.
Dynamodb data items can be accessed in two ways like :
- Scan Operation
- Query Operation
The scan operation on a Dynamodb table with a large number of item count results in ineffective utilization of provisioned throughput where we seek the aid of Global Secondary index to define a new primary key combination of “Name” as Hash Key and “monthvalue” as sort Key. While doing so, the data retrieval of records of a user for a particular month from a query operation is easy and have been efficient;
Table 3: final_recruitment_portal
Main Table:
Hash Key: Uid
This table stores the details of every user of the application. Each user is made identical with each other with the username attribute. Thus, the best option for a primary hash key is to user uid itself.
2. Monitoring and alerting for read and write capacity:
Cloudwatch Alarms are created to notify the system (us) about:
Insufficiency caused in provisioned throughput capacity.
3. Enable Continuous Backup and Data Encryption
Continuous backup, which is enabled in our system, provides point-in-time recovery Backup for a continuous data backup until it is explicitly turned off. By default, dynamodb maintains the continuous backups of the table for the last 35 days. We have enabled the encryption in our database for the security purpose.
4. Workload
The workload for our current system in Dynamodb are as follows:
- Write Capacity Units: Range between 20,000 to 25,000 WCU-Hrs
- Read Capacity Units: Range between 20,000 to 25,000 RCU-Hrs
- Total data storage: less than 5 GB till now
- Global deployment: In only one region (ap-south-1)
5. Data Access patterns and Transaction Volumes:
Our application may require to scan or query the table item to get the stored data. Thus the data access patterns primarily depend upon the usage of the indexes upon which the database has been designed. Generally, we have used the Global secondary indexes on which hash keys and the sort keys have been defined.
6. Deployment Pattern:
Since the use of the database is new to any of the system we implement on. The applications use the dynamodb database as their new primary database which is easy to use and apply for its no SQL feature implementation.
7. Description of any challenge or customer objection overcome to drive a DynamoDB adoption:
This service was quite suitable with the use case of our client project there were not many obstacles created by the client side. The problem only was if the service could work perfectly after the integration with their service.
